
Databáza FinStat.sk obsahuje dáta o stovkách tisícov slovenských spoločností a podnikateľských subjektov. Svojim klientom umožňuje prehliadať informácie rôzneho charakteru z desiatok dátových zdrojov.

Od surových dát k užívateľovi: ako udržiavať a rýchlo sprístupniť stovky gigabajtov živých dát
Databáza FinStat.sk obsahuje dáta o stovkách tisícov slovenských spoločností a podnikateľských subjektov. Svojim klientom umožňuje prehliadať informácie rôzneho charakteru z desiatok dátových zdrojov.
Okrem vyhľadávania, prehliadania a filtrovania v spoločnostiach poskytuje aj službu monitorovania, pri ktorej dostane užívateľ pri akejkoľvek zmene v spoločnostiach, o ktoré má záujem, informáciu mailom.
Spracovať takéto veľké množstvo rôznorodých zdrojov a udržať to všetko aktuálne a rýchle prináša rôzne špecifické výzvy. Poďme sa na tieto výzvy pozrieť.
Zo zdroja do databázy
Na počiatku každého dielika dátového puzzle o spoločnostiach sú surové dáta viacerých dátových zdrojov. Môže to byť obchodný register, obchodný vestník, register úpadcov, či zoznam neplatičov zdravotného poistenia.
Rôzne zdroje poskytujú dáta v rozličných formátoch. Často to bývajú strojovo spracovateľné formáty, ako napríklad XML, ale niekedy treba dáta dolovať z textov podaní, stránok, alebo dokonca PDF dokumentov.
Z tejto surovej formy sa dáta predspracujú do štruktúrovanej podoby a uložia do databázy. Pre rôzne prípady použitia existujú zabehnuté patterny ukladania dát: ak treba pridať k subjektu jednoduchú vlastnosť, môže ísť o jednoduché rozšírenie entity. Ak je vlastností viac, bude treba pridať nový komplexný dokument. Ak treba informácie evidovať historicky, takýto dokument musí podporovať historický formát, ktorý vedia spracovať ostatné systémy.
To všetko sa pri pravidelných importoch ukladá do databázy, ktorá postupným pridávaním dátových zdrojov a dát rastie na objeme.
Aktuálna veľkosť databázy je v stovkách gigabajtov dát, a rýchlosť rastu ani po rokoch neustáva.
Z primárneho úložiska do indexov

Použitá terminológia naznačuje, že na ukladanie dát sa nepoužíva SQL databáza, tabuľky, stĺpce a riadky, ale NoSQL databáza a dokumenty. V prípade FinStatu je to databáza RavenDB, ktorá okrem základných funkcionalít (uloženie dokumentu, načítanie dokumentu), poskytuje široké spektrum funkcionalít, ktoré sa v rôznej miere podieľajú na fungovaní celého projektu.
Jedným z najdôležitejších aspektov spracovania dát je indexácia. Aby bolo možné obsluhovať požiadavky užívateľov dostatočne rýchlo, je potrebné všetky relevantné dáta zduplikovať do indexov, ktoré umožňujú dostatočne rýchlo dáta filtrovať, zoraďovať a následne zobraziť užívateľovi.
Veľká väčšina dát je spracovaná pomocou vstavaných map-reduce indexov, ktoré dokážu zobrať dáta rôznych tvarov a veľkostí, a zosumarizovať ich podľa naprogramovanej logiky do jedného logického celku. Ako príklad poslúži dokument firmy so základnými registračnými údajmi, k nemu prislúchajúci osobitný dokument obsahujúci historické dlhy voči verejným inštitúciám, a ďalej množina ďalších dokumentov, ktoré obsahujú informácie o prebiehajúcom konkurznom konaní.
Map časť postupne načítava dokumenty všetkých zdrojových kolekcií, a tieto namapuje do spoločného tvaru. V reduce kroku sú tieto dáta agregované do skupín, typicky podľa identifikačného čísla spoločnosti.
Analógiou reduce v SQL svete je GROUP BY. Počas tejto agregácie sa môžu dáta spracúvať podľa potreby - pre dlhy sa spočíta celková suma dlhov, pre konkurzné konanie sa vyberie najrelevantnejší dátum začiatku a konca konania, spracuje sa zoznam veriteľov, atď.
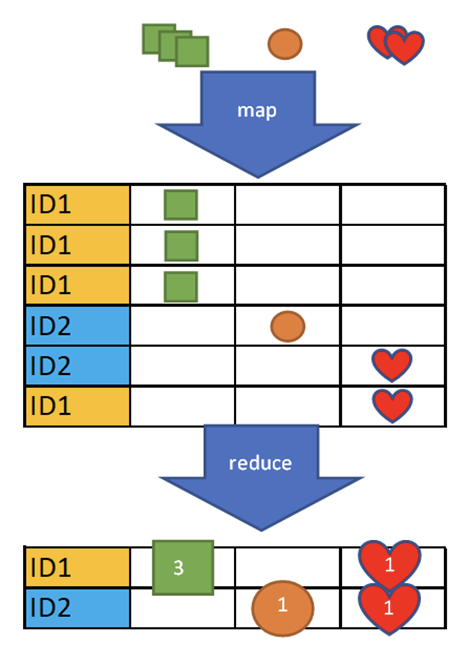
Výsledkom sú zindexované dáta, nad ktorými je možné veľmi rýchlo a efektívne vyhľadávať, filtrovať a zoraďovať získané dáta.
Indexy potom v databázach FinStatu zaberajú približne dvojnásobné množstvo diskového priestoru oproti pôvodným dátam. Z celkovej veľkosti databázy viac ako 1 TB je to až 600 GB dát určených len pre indexy.
Ukladanie dát duplicitne a denormalizovane je v tomto prípade daňou za rýchlosť čítania, flexibilitu a možnosť škálovania.
Z databázy na obrazovku
Celý technologický stack FinStatu je postavený na .NET ekosystéme, a ten sa neustále vyvíja. Pravidelne investujeme čas do vývoja, aby sme aplikácie udržiavali na aktuálnych verziách frameworkov a knižníc. Nie je to nevyhnutná práca, odmenou za to ale je zvýšenie výkonu pri každej novej verzii. Okrem toho aj zlepšenie čitateľnosti a udržiateľnosti kódu pri využívaní noviniek, ktoré prináša jazyk a celé prostredie .NET.
Okrem hlavnej aplikácie webového portálu (ASP.NET Core) sa o funkčnosť stará plejáda importovacích a spracúvajúcich programov. Tiež aj niekoľko pomocných programov pre správu súčastí systému a odosielanie mailových notifikácií, ktoré nevyužívajú len NoSQL databázu RavenDB, ale aj klasické databázy MSSQL a PostgreSQL.
Produkčná infraštruktúra je kompletne hostovaná v Microsoft Azure, čo odstraňuje potrebu riešiť problémy, ktoré nesúvisia s doménou finančných a firemných dát, a priamo so spracovaním dát.
Ďalšie ciele
Okrem slovenského portálu FinStat.sk je aktuálne rozpracovaná česká verzia, ktorá má ambíciu spracovať otvorené dáta v Česku, a sprístupniť ich ľuďom podobným spôsobom, ako sa to podarilo na Slovensku.
Technologické výzvy sú aj tu podobné, a preto sú zvolené riešenia analógiou tých, ktoré sú úspešne použité na slovenskej verzii.
Firma FinStat ale nezostale len pri slovenských a českých dátach. V rámci expanzie na zahraničné trhy vznikol projekt HitHorizons.com, ktorého cieľom je poskytovať registračné dáta firiem v celoeurópskom meradle, a v budúcnosti možno celosvetovo. Dostupnosť dát v globálnom kontexte je rozdielna a aj rozsah dát je zásadne iný. Preto aj náš prístup bol k ich spracovaniu musel byť rozdielny.
Databáza obsahuje rádovo vyššie množstvo záznamov, čo je bohužiaľ vyvážené menším rozsahom dát o konkrétnom subjekte. V súhrne ide o ohromné množstvo dát, ktoré nás donútilo zmeniť spôsob ukladania dát, ako aj spôsob ich sprístupnenia zákazníkom. Zákazník dostáva do ruk nástroje, ktoré mu umožnia zorientovať sa v enormnom množstve dát a dostať sa k informáciám, ktoré potrebuje.
Nástroje zahŕňajú jednoduché vyhľadávanie a prezeranie subjektov, API pre integráciu do vlastných systémov, pokročilé nástroje na segmentáciu a analýzu trhu, ako aj niekoľko špecifických riešení pre riešenie konkrétnych problémov pri hromadnom alebo individuálnom prieskume spoločností.
Other posts from CodeCon
- 2023-12-19CODECON #Žilina: Vízia a inovácie v rozvoji developerskej komunity na Slovensku
- 2023-11-27Čo si pre teba prichystal GoodRequest na premiérovom CodeCon Žilina?
- 2023-11-27Datapac - vytvárame prostredie významné svojim spiritom!
- 2023-11-27Predefinovanie pracovného výkonu: Dell Precision pracovné stanice menia profesionálnu produktivitu
- 2023-11-27Éra Titanov praje aj novému CodeConu v Žiline
- 2023-11-22CODECON #Žilina - Organizačné informácie
- 2023-11-215 jednoduchých tipov, ako zlepšiť váš agilný vývoj
- 2023-11-16KROS na CODECONe
- 2023-11-16Ako sme sa pustili do revolúcie v parkovaní
- 2023-11-15InfoConsulting - firma s dlhou tradíciou vo svete IT